Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Join the event that trusts business leaders for almost two decades. VB Transform brings together people who build a real business AI strategy. Learn more
Minimal Chinese AI startup, perhaps better known in the West for its realistic success Oh Hailuo video modelpublished his latest model of great language, Minimax-M1 – and in good news for businesses and developers, it’s completely Open Source under APACHE 2.0 licenseThis means that companies can take and use it for commercial applications and modify it to their taste without restriction or payment.
M1 is an open offer that establishes new standards in long -term reasoning, the use of agency tools and effective calculation performance. It is available today on the AI code sharing community Face And Microsoft’s rival code shares the GitHub communityThe first version of what the company nicknamed “Minimaxweek” of its social account on X – with other announcements of expected products.
Minimax-M1 is distinguished by a context window of 1 million input tokens and up to 80,000 tokens at output, positioning it as one of the most extensive models available for long-context reasoning tasks.
The “context window” in large -language models (LLMS) refers to the maximum number of tokens that the model can treat at the same time – including input and output. The tokens are the basic units of the text, which may include whole words, words of words, punctuation marks or code symbols. These tokens are converted into digital vectors that the model uses to represent and manipulate the meaning through its parameters (weight and bias). They are, in essence, the mother tongue of the LLM.
As a comparison, OPENAI GPT-4O has a context window of only 128,000 tokens – enough to exchange About the value of an information novel Between the user and the model in a single back and forth interaction. At 1 million tokens, the minimum-m1 could exchange a small collection or worthy of information from the book series. Google Gemini 2.5 PRO offers a higher upper limit of 1 million token contextAlso, with a window of 2 million work reported.
But M1 has another tip in its round: it was formed using learning to strengthen in an innovative, ingenious and very efficient technique. The model is formed using a hybrid reduction mixture architecture (MOE) with a lightning attention mechanism designed to reduce the costs of inference.
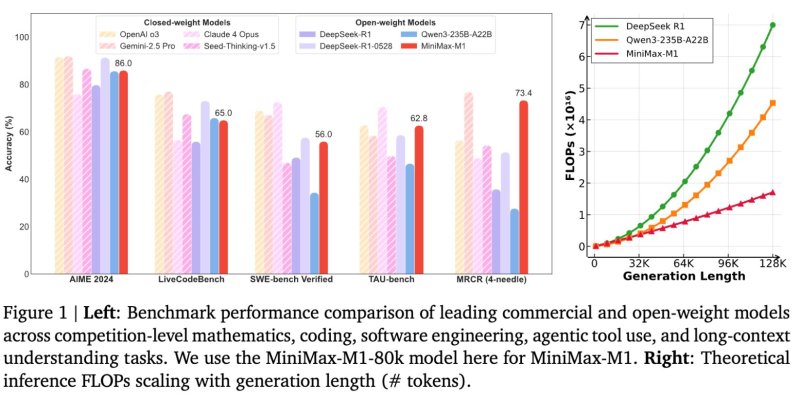
According to the technical report, Minimax-M1 consumes only 25% of the floating points operations (flops) required by Deepseek R1 At a length of generation of 100,000 tokens.
The model is available in two variants-Minimax-M1-40K and Minimax-M1-80K-referring to their “reflection budgets” or their exit lengths.
The architecture is built on the anterior base of text-text-01 of the company and includes 456 billion parameters, with 45.9 billion activated by token.
A remarkable feature of the version is the training cost of the model. Minimax reports that the M1 model has been formed using large -scale strengthening learning (RL) to an efficiency rarely observed in this area, with a total cost of $ 534,700.
This efficiency is credited on a personalized RL algorithm called Cispo, which cuts the importance of sampling weights rather than tokens updates, and to the design of hybrid attention which helps to rationalize the scaling.
It is a surprisingly “cheap” amount for an LLM border, because Deepseek has formed its R1 reasoning model to a Cost declared from $ 5 to 6 millionWhile the training cost of the GPT -4 of Openais – a model of more than two years now – was said to exceed $ 100 million. This cost comes from both the price of graphic processing units (GPU), from the computer equipment massively parallel mainly manufactured by companies like NVIDIA, which can cost $ 20,000 to $ 30,000 or more per module, and from the energy required to execute these chips continuously in large -scale data centers.
Minimax-M1 was evaluated in a series of established benchmarks that test advanced reasoning, software engineering and tools for using tools.

On AIME 2024, a reference in mathematics competitions, the M1-80K model obtains an accuracy of 86.0%. It also offers solid performance in coding and long -term context tasks, realizing:

These results place minimax-M1 before other open competitors such as Deepseek-R1 and QWEN3-23B-A22B On several complex tasks.
While models of closed weights like O3 and Gemini 2.5 Pro of OPENAI are always at the top of the reference, Minimax-M1 considerably shrinks the performance difference while remaining freely accessible under a Apache-2.0 license.
For deployment, Minimax recommends VLLM as a service backend, citing its optimization for important workloads, the effectiveness of memory and the handling of demands. The company also offers deployment options using the Transformers library.
Minimax-M1 includes structured function call capacities and is packed with a chatbot API with online search, video and image generation, speech and vocal cloning tools. These features aim to take charge of broader agentic behavior in real world applications.
The free access capacities of Minimax-M1, long context capacities and calculation efficiency are several recurring challenges for technical professionals responsible for the management of large-scale AI systems.
For engineering prospects responsible for the full LLM life cycle – such as optimization of model performance and deployment within tight deadlines – Minimax -M1 offers a lower operational cost profile while taking charge of advanced reasoning tasks. Its long context window could considerably reduce pre -treatment for corporate documents or newspaper data that extend over dozens or hundreds of thousands of tokens.
For those who manage the AI orchestration pipelines, the possibility of adjusting and deploying Minimax-M1 using established tools like VLLM or Transformers supports easier integration into the existing infrastructure. The architecture of hybrid attention can help simplify the scaling strategies, and the competitive performance of the model on the reasoning in several stages and the references in software engineering offers a high capacity base for internal co -pilots or systems based on agents.
From the point of view of the data platform, the teams responsible for maintaining an efficient and scalable infrastructure can benefit from the M1 support for structured function calls and its compatibility with automated pipelines. Its open source nature allows teams to adapt the performance to their shamelessly locking of the supplier.
The safety tracks can also find the value in the evaluation of the M1 potential for the secure and local deployment of a high -capacity model which is not based on the transmission of data sensitive to the third party termination criteria.
Overall, Minimax-M1 presents a flexible option for organizations that seek to experiment or increase the advanced AI capacities while managing costs, remaining within operational limits and avoiding proprietary stresses.
The version points out the minimax accent on practical and evolutionary evolution models. By combining open access with advanced architecture and calculation efficiency, Minimax-M1 can serve as a fundamental model for developers creating new generation applications which require both a reasoning depth and an understanding of long-range inputs.
We will follow the other versions of minimax throughout the week. Stay listening!




