Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

This article is part of VentureBeat’s special issue, “The Real Cost of AI: Performance, Efficiency and ROI at Scale.” Read more from this special issue.
AI pilots rarely start with a deep discussion of infrastructure and hardware. But seasoned scalers warn that deploying high-value production workloads will not end happily without strategic, ongoing focus on a key enterprise-grade foundation.
Good news: There’s growing recognition by enterprises about the pivotal role infrastructure plays in enabling and expanding generative, agentic and other intelligent applications that drive revenue, cost reduction and efficiency gains.
According to IDC, organizations in 2025 have boosted spending on compute and storage hardware infrastructure for AI deployments by 97% compared to the same period a year before. Researchers predict global investment in the space will surge from $150 billion today to $200 billion by 2028.
But the competitive edge “doesn’t go to those who spend the most,” John Thompson, best-selling AI author and head of the gen AI Advisory practice at The Hackett Group said in an interview with VentureBeat, “but to those who scale most intelligently.”
Other experts agree, saying that chances are slim-to-none that enterprises can expand and industrialize AI workloads without careful planning and right-sizing of the finely orchestrated mesh of processors and accelerators, as well as upgraded power and cooling systems. These purpose-built hardware components provide the speed, availability, flexibility and scalability required to handle unprecedented data volume, movement and velocity from edge to on-prem to cloud.
Source: VentureBeat
Study after study identifies infrastructure-related issues, such as performance bottlenecks, mismatched hardware and poor legacy integration, alongside data problems, as major pilot killers. Exploding interest and investment in agentic AI further raise the technological, competitive and financial stakes.
Among tech companies, a bellwether for the entire industry, nearly 50% have agent AI projects underway; the rest will have them going in 24 months. They are allocating half or more of their current AI budgets to agentic, and many plan further increases this year. (Good thing, because these complex autonomous systems require costly, scarce GPUs and TPUs to operate independently and in real time across multiple platforms.)
From their experience with pilots, technology and business leaders now understand that the demanding requirements of AI workloads — high-speed processing, networking, storage, orchestration and immense electrical power — are unlike anything they’ve ever built at scale.
For many enterprises, the pressing question is, “Are we ready to do this?” The honest answer will be: Not without careful ongoing analysis, planning and, likely, non-trivial IT upgrades.
Like snowflakes and children, we’re reminded that AI projects are similar yet unique. Demands differ wildly between various AI functions and types (training versus inference, machine learning vs reinforcement). So, too, do wide variances exist in business goals, budgets, technology debt, vendor lock-in and available skills and capabilities.
Predictably, then, there’s no single “best” approach. Depending on circumstances, you’ll scale AI infrastructure up or horizontally (more power for increased loads), out or vertically (upgrading existing hardware) or hybrid (both).
Nonetheless, these early-chapter mindsets, principles, recommendations, practices, real-life examples and cost-saving hacks can help keep your efforts aimed and moving in the right direction.
It’s a sprawling challenge, with lots of layers: data, software, networking, security and storage. We’ll keep the focus high-level and include links to helpful, related drill-downs, such as those above.
The biggest mindset shift is adopting a new conception of AI — not as a standalone or siloed app, but as a foundational capability or platform embedded across business processes, workflows and tools.
To make this happen, infrastructure must balance two important roles: Providing a stable, secure and compliant enterprise foundation, while making it easy to quickly and reliably field purpose-built AI workloads and applications, often with tailored hardware optimized for specific domains like natural language processing (NLP) and reinforcement learning.
In essence, it’s a major role reversal, said Deb Golden, Deloitte’s chief innovation officer. “AI must be treated like an operating system, with infrastructure that adapts to it, not the other way around.”
She continued: “The future isn’t just about sophisticated models and algorithms. Hardware is no longer passive. [So from now on], infrastructure is fundamentally about orchestrating intelligent hardware as the operating system for AI.”
To operate this way at scale and without waste requires a “fluid fabric,” Golden’s term for the dynamic allocation that adapts in real-time across every platform, from individual silicon chips up to complete workloads. Benefits can be huge: Her team found that this approach can cut costs by 30 to 40% and latency by 15 to 20%. “If your AI isn’t breathing with the workload, it’s suffocating.”
It’s a demanding challenge. Such AI infrastructure must be multi-tier, cloud-native, open, real-time, dynamic, flexible and modular. It needs to be highly and intelligently orchestrated across edge and mobile devices, on-premises data centers, AI PCs and workstations, and hybrid and public cloud environments.
What sounds like buzzword bingo represents a new epoch in the ongoing evolution, redefining and optimizing enterprise IT infrastructure for AI. The main elements are familiar: hybrid environments, a fast-growing universe of increasingly specialized cloud-based services, frameworks and platforms.
In this new chapter, embracing architectural modularity is key for long-term success, said Ken Englund, EY Americas technology growth leader. “Your ability to integrate different tools, agents, solutions and platforms will be critical. Modularity creates flexibility in your frameworks and architectures.”
Decoupling systems components helps future-proof in several ways, including vendor and technology agnosticism, lug-and-play model enhancement and continuous innovation and scalability.
Enterprise technology teams looking to expand their use of enterprise AI face an updated Goldilocks challenge: Finding the “just right” investment levels in new, modern infrastructure and hardware that can handle the fast-growing, shifting demands of distributed, everywhere AI.
Under-invest or stick with current processing capabilities? You’re looking at show-stopping performance bottlenecks and subpar business outcomes that can tank entire projects (and careers).
Over-invest in shiny new AI infrastructure? Say hello to massive capital and ongoing operating expenditures, idle resources and operational complexity that nobody needs.
Even more than in other IT efforts, seasoned scalers agreed that simply throwing processing power at problems isn’t a winning strategy. Yet it remains a temptation, even if not fully intentional.
“Jobs with minimal AI needs often get routed to expensive GPU or TPU infrastructure,” said Mine Bayrak Ozmen, a transformation veteran who’s led enterprise AI deployments at Fortune 500 companies and a Center of AI Excellence for a major global consultancy.
Ironically, said Ozmen, also co-founder of AI platform company Riernio, “it’s simply because AI-centric design choices have overtaken more classical organization principles.” Unfortunately, the long-term cost inefficiencies of such deployments can get masked by deep discounts from hardware vendors, she said.
What, then, should guide strategic and tactical choices? One thing that should not, experts agreed, is a paradoxically misguided reasoning: Because infrastructure for AI must deliver ultra-high performance, more powerful processors and hardware must be better.
“AI scaling is not about brute-force compute,” said Hackett’s Thompson, who has led numerous large global AI projects and is the author of The Path to AGI: Artificial General Intelligence: Past, Present, and Future, published in February. He and others emphasize that the goal is having the right hardware in the right place at the right time, not the biggest and baddest everywhere.
According to Ozmen, successful scalers employ “a right-size for right-executing approach.” That means “optimizing workload placement (inference vs. training), managing context locality, and leveraging policy-driven orchestration to reduce redundancy, improve observability and drive sustained growth.”
Sometimes the analysis and decision are back-of-a-napkin simple. “A generative AI system serving 200 employees might run just fine on a single server,” Thomspon said. But it’s a whole different case for more complex initiatives.
Take an AI-enabled core enterprise system for hundreds of thousands of users worldwide, requiring cloud-native failover and serious scaling capabilities. In these cases, Thompson said, right-sizing infrastructure demands disciplined, rigorous scoping, distribution and scaling exercises. Anything else is foolhardy malpractice.
Surprisingly, such basic IT planning discipline can get skipped. It’s often companies, desperate to gain a competitive advantage, that try to speed up things by aiming outsized infrastructure budgets at a key AI project.
New Hackett research challenges some basic assumptions about what is truly needed in infrastructure for scaling AI, providing additional reasons to conduct rigorous upfront analysis.
Thompson’s own real-world experience is instructive. Building an AI customer support system with over 300,000 users, his team soon realized it was “more important to have global coverage than massive capacity in any single location.” Accordingly, infrastructure is located across the U.S., Europe and the Asia-Pacific region; users are dynamically routed worldwide.
The practical takeaway advice? “Put fences around things. Is it 300,000 users or 200? Scope dictates infrastructure,” he said.
A modern multi-tiered AI infrastructure strategy relies on versatile processors and accelerators that can be optimized for various roles across the continuum. For helpful insights on choosing processors, check out Going Beyond GPUs.
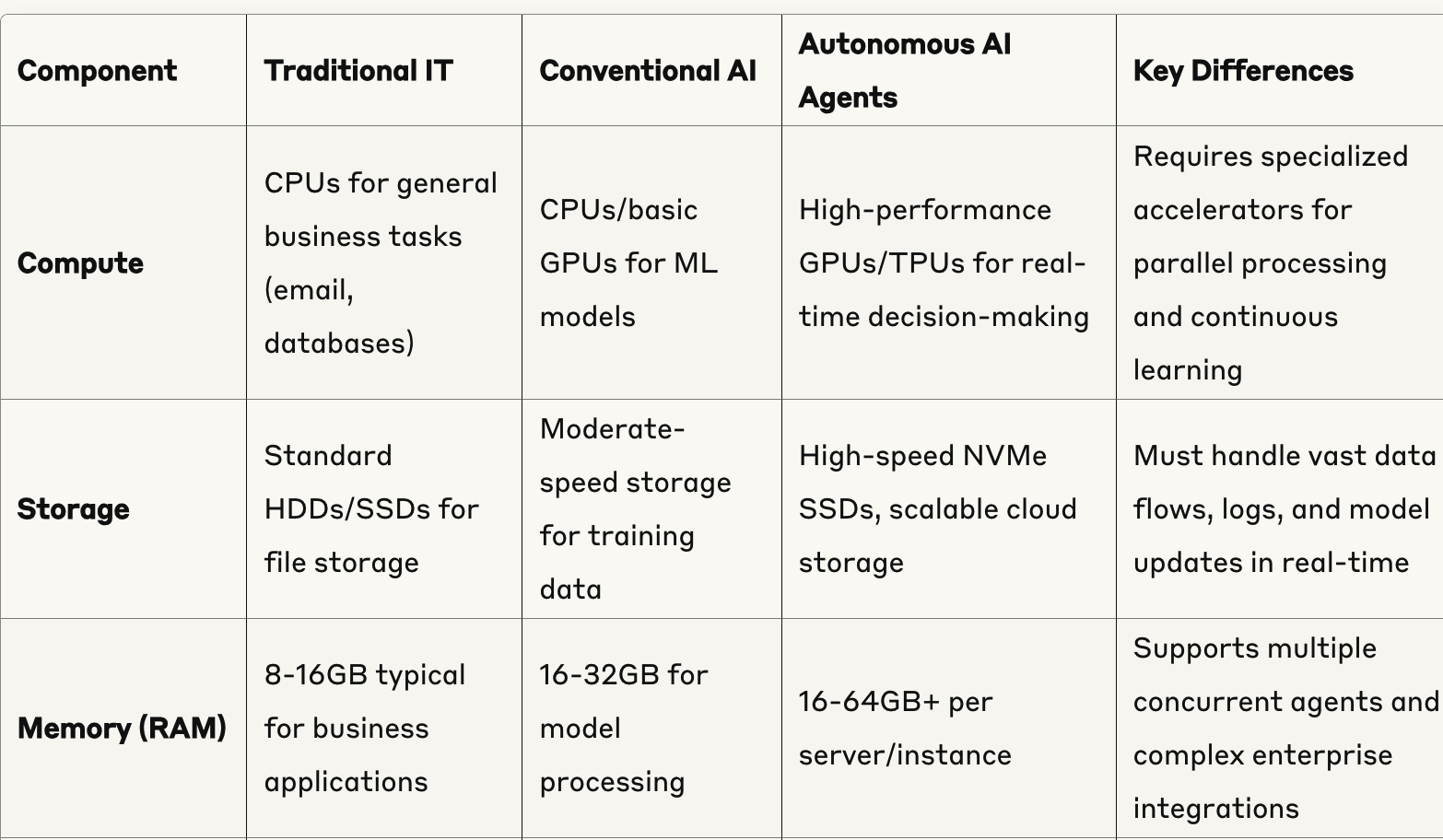
Source: VentureBeat
You’ve got a fresh picture of what AI scaling infrastructure can and should be, a good idea about the investment sweet spot and scope, and what’s needed where. Now it’s time for procurement.
As noted in VentureBeat’s last special issue, for most enterprises, the most effective strategy will be to continue using cloud-based infrastructure and equipment to scale AI production.
Surveys of large organizations show most have transitioned from custom on-premises data centers to public cloud platforms and pre-built AI solutions. For many, this represents a next-step continuation of ongoing modernization that sidesteps big upfront capital outlays and talent scrambles while providing critical flexibility for quickly changing requirements.
Over the next three years, Gartner predicts ,50% of cloud compute resources will be devoted to AI workloads, up from less than 10% today. Some enterprises are also upgrading on-premises data centers with accelerated compute, faster memory and high-bandwidth networking.
The good news: Amazon, AWS, Microsoft, Google and a booming universe of specialty providers continue to invest staggering sums in end-to-end offerings built and optimized for AI, including full -stack infrastructure, platforms, processing including GPU cloud providers, HPC, storage (hyperscalers plus Dell, HPE, Hitachi Vantara), frameworks and myriad other managed services.
Especially for organizations wanting to dip their toes quickly, said Wyatt Mayham, lead AI consultant at Northwest AI Consulting, cloud services offer a great, low-hassle choice.
In a company already running Microsoft, for example, “Azure OpenAI is a natural extension [that] requires little architecture to get running safely and compliantly,” he said. “It avoids the complexity of spinning up custom LLM infrastructure, while still giving companies the security and control they need. It’s a great quick-win use case.”
However, the bounty of options available to technology decision-makers has another side. Selecting the appropriate services can be daunting, especially as more enterprises opt for multi-cloud approaches that span multiple providers. Issues of compatibility, consistent security, liabilities, service levels and onsite resource requirements can quickly become entangled in a complex web, slowing development and deployment.
To simplify things, organizations may decide to stick with a primary provider or two. Here, as in pre-AI cloud hosting, the danger of vendor lock-in looms (although open standards offer the possibility of choice). Hanging over all this is the specter of past and recent attempts to migrate infrastructure to paid cloud services, only to discover, with horror, that costs far surpass the original expectations.
All this explains why experts say that the IT 101 discipline of knowing as clearly as possible what performance and capacity are needed – at the edge, on-premises, in cloud applications, everywhere – is crucial before starting procurement.
Conventional wisdom suggests that handling infrastructure internally is primarily reserved for deep-pocketed enterprises and heavily regulated industries. However, in this new AI chapter, key in-house elements are being re-evaluated, often as part of a hybrid right-sizing strategy.
Take Microblink, which provides AI-powered document scanning and identity verification services to clients worldwide. Using Google Cloud Platform (GCP) to support high-throughput ML workloads and data-intensive applications, the company quickly ran into issues with cost and scalability, said Filip Suste, engineering manager of platform teams. “GPU availability was limited, unpredictable and expensive,” he noted.
To address these problems, Suste’s teams made a strategic shift, moving computer workloads and supporting infrastructure on-premises. A key piece in the shift to hybrid was a high-performance, cloud-native object storage system from MinIo.
For Microblink, taking key infrastructure back in-house paid off. Doing so cut related costs by 62%, reduced idle capacity and improved training efficiency, the company said. Crucially, it also regained control over AI infrastructure, thereby improving customer security.
Makino, a Japanese manufacturer of computer-controlled machining centers operating in 40 countries, faced a classic skills gap problem. Less experienced engineers could take up to 30 hours to complete repairs that more seasoned workers can do in eight.
To close the gap and improve customer service, leadership decided to turn two decades of maintenance data into instantly accessible expertise. The fastest and most cost-effective solution, they concluded, is to integrate an existing service-management system with a specialized AI platform for service professionals from Aquant.
The company says taking the easy technology path produced great results. Instead of laboriously evaluating different infrastructure scenarios, resources were focused on standardizing lexicon and developing processes and procedures, Ken Creech, Makino’s director of customer support, explained.
Remote resolution of problems has increased by 15%, solution times have decreased, and customers now have self-service access to the system, Creech said. “Now, our engineers ask a plain-language question, and the AI hunts down the answer quickly. It’s a big wow factor.”
At Albertsons, one of the nation’s largest food and drug chains, IT teams employ several simple but effective tactics to optimize AI infrastructure without adding new hardware, said Chandrakanth Puligundla, tech lead for data analysis, engineering and governance.
Gravity mapping, for example, shows where data is stored and how it’s moved, whether on edge devices, internal systems or on multi-cloud systems. This knowledge not only reduces egress costs and latency, Puligundla explained, but guides more informed decisions about where to allocate computing resources.
Similarly, he said, using specialist AI tools for language processing or image identification takes less space, often delivering better performance and economy than adding or updating more expensive servers and general-purpose computers.
Another cost-avoidance hack: Tracking watts per inference or training hour. Looking beyond speed and cost to energy-efficiency metrics prioritizes sustainable performance, which is crucial for increasingly power-thirsty AI models and hardware.
Puligundla concluded: “We can really increase efficiency through this kind of mindful preparation.”
The success of AI pilots has brought millions of companies to the next phase of their journeys: Deploying generative and LLMs, agents and other intelligent applications with high business value into wider production.
The latest AI chapter promises rich rewards for enterprises that strategically assemble infrastructure and hardware that balances performance, cost, flexibility and scalability across edge computing, on-premises systems and cloud environments.
In the coming months, scaling options will expand further, as industry investments continue to pour into hyper-scale data centers, edge chips and hardware (AMD, Qualcomm, Huawei), cloud-based AI full-stack infrastructure like Canonical and Guru, context-aware memory, secure on-prem plug-and-play devices like Lemony, and much more.
How wisely IT and business leaders plan and choose infrastructure for expansion will determine the heroes of company stories and the unfortunates doomed to pilot purgatory or AI damnation.




