Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Join the event that trusts business leaders for almost two decades. VB Transform brings together people who build a real business AI strategy. Learn more
While models of large languages (LLM) master the text (and other methods to a certain extent), they do not have the physical “common sense” to function in dynamic and real environments. This has limited the deployment of AI to fields such as manufacturing and logistics, where understanding of the cause and the effect is essential.
Meta’s latest model, V-jepa 2takes a step towards filling it with this gap by learning a world model from video and physical interactions.
V-Ipa 2 can help create AI applications that require predicting the results and planning actions in unpredictable environments with many cases. This approach can provide a clear path to more capable robots and advanced automation in physical environments.
Humans develop physical intuition at the start of life by observing their environment. If you see a ball launched, you instinctively know its trajectory and can predict where it will land. V-Ipa 2 learns a similar “global model”, which is the internal simulation of an AI system on the functioning of the physical world.
The model is built on three basic capacities which are essential for corporate applications: understand what is happening in a scene, predict how the scene will change according to an action and plan a sequence of actions to achieve a specific objective. As meta-states in his blogHis “long -term vision is that the world models will allow AI agents to plan and reason in the physical world”.
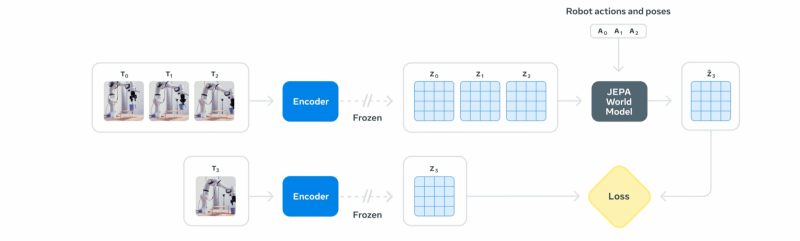
The architecture of the model, called the predictive architecture of video integration (V-Jepa), consists of two key parts. A “encoder” looks at a video clip and the condensed in a compact digital summary, called integration. This integration captures essential information on objects and their relationships in the scene. A second component, the “predictor”, then takes this summary and imagines how the scene will evolve, generating a prediction of what the next summary will look like.

This architecture is the latest evolution of the Jepa frame, which was first applied to images with Idipp And now advances to the video, demonstrating a coherent approach to the construction of world models.
Unlike generative AI models that try to predict the exact color of each pixel in a future setting – an intensive task in calculation – V -Jepa 2 works in an abstract space. It focuses on forecasting the high level characteristics of a scene, such as the position and trajectory of an object, rather than its details of texture or background, which makes it much more effective than other larger models at only 1.2 billion parameters
This results in a reduction in calculation costs and makes it more suitable for deployment in parameters of the real world.
V-jepa 2 is formed in two steps. First, he strengthens his fundamental understanding of physics through self-supervised learningLooking at more than a million hours of unmarked internet videos. By simply observing how objects move and interact, it develops a world model for general use without any human direction.
In the second step, this pre-formed model is refined on a small set of specialized data. By processing only 62 hours of video showing a robot performing tasks, as well as the corresponding control controls, V-J-Ja learns to connect specific actions to their physical results. The result is a model that can plan and control actions in the real world.

This two -step training allows a critical capacity for the automation of the real world: the planning of zero robots. A robot propelled by V-Jepa 2 can be deployed in a new environment and successfully manipulate objects that he has never encountered before, without having to be recycled for this specific parameter.
This is an important advance on previous models that required training data exact Robot and environment they operate. The model was formed on an open source data set, then successfully deployed on different robots in Meta laboratories.
For example, to accomplish a task like collecting an object, the robot receives a goal image of the desired result. He then uses the predictor V-Jepa 2 to internally simulate a range of possible movements possible. It marks each imaginary action according to the proximity of the objective, performs the best rated action and repeats the process until the task is finished.
Using this method, the model has reached success rates between 65% and 80% on pick-and-place tasks with unknown objects in new parameters.
This ability to plan and act in new situations has direct implications for commercial operations. In logistics and manufacturing, it allows more adaptable robots which can manage variations in products and warehouse arrangements without in -depth reprogramming. This can be particularly useful because companies explore the deployment of Humanoid robots in factories and mounting lines.
The same world model can feed very realistic digital twins, allowing companies to simulate new processes or train other AI in a physically precise virtual environment. In industrial contexts, a model could monitor the video flows of the machines and, depending on its understanding learned from physics, predict safety problems and failures before they occur.
This research is a key step towards what Meta calls “Advanced Machine Intelligence (AMI)”, where AI systems can “find out about the world as humans do, plan how to perform unknown tasks and adapt effectively to the constantly evolving world around us.”
Meta has published the model and its training code and hopes to “build a large community around this research, which has progressed towards our ultimate goal of developing global models which can transform the way in which AI interacts with the physical world.”
V-Ipa 2 approaches the robotics of the model defined by the software that the cloud teams already recognize: pre-train once, deploys anywhere. Since the model learns the general physics of public video and only needs a few tens of hours of specific sequences, companies can reduce the data collection cycle which generally leads to pilot projects. In practical terms, you can prototyper a pick-and-placing robot on an affordable office arm, then launch the same policy on an industrial platform on the factory floor without gathering thousands of fresh samples or writing personalized motion scripts.
Lower general training costs reshape the costs equation. At 1.2 billion parameters, V-Ipa 2 adapts comfortably to a single high-end GPU, and its abstract prediction targets further reduce the inference load. This allows the teams to run a closed on -site loop or on -site control, avoiding the cloud latency and the headacheacle that is delivered with a streaming video outside the plant. The budget that once went to massive calculation clusters can rather finance additional sensors, redundancies or faster iteration cycles.




